This demo introduces Schron, which is an end-to-end speech synthesis based on deep conditional Schrödinger bridges.
Speech synthesis plays an important role in human-computer interaction. Existing methods mainly employ traditional two-stage pipeline, e.g. text-to-speech and vocoder. In this paper, we propose a system called Schron, which can generate speech waves in an end-to-end mamaner by solving Schrodinger bridge problems (SBP). In order to make SBP suitable for speech synthesis, we generalize SBP from two aspects. The first generalization makes it possible to accept condition variables, which are used to control the generated speech, and the second generalization allows it to handle variable-size input. Besides these two generalizations, we propose two techniques to fill the large information gap between text and speech waveforms for generating high-quality voice. The first technique is to use a text-mel joint representation as the conditional input of the conditional SBP. The second one is to use a branch network for the generation of mel scores as a regularization, so that the text features will not be degenerated. Experimental results show that Schron achieves state-of-the-art MOS of 4.52 on public data set LJSpeech.
Frameworks, pipelines, modules, and algorithms in Schron
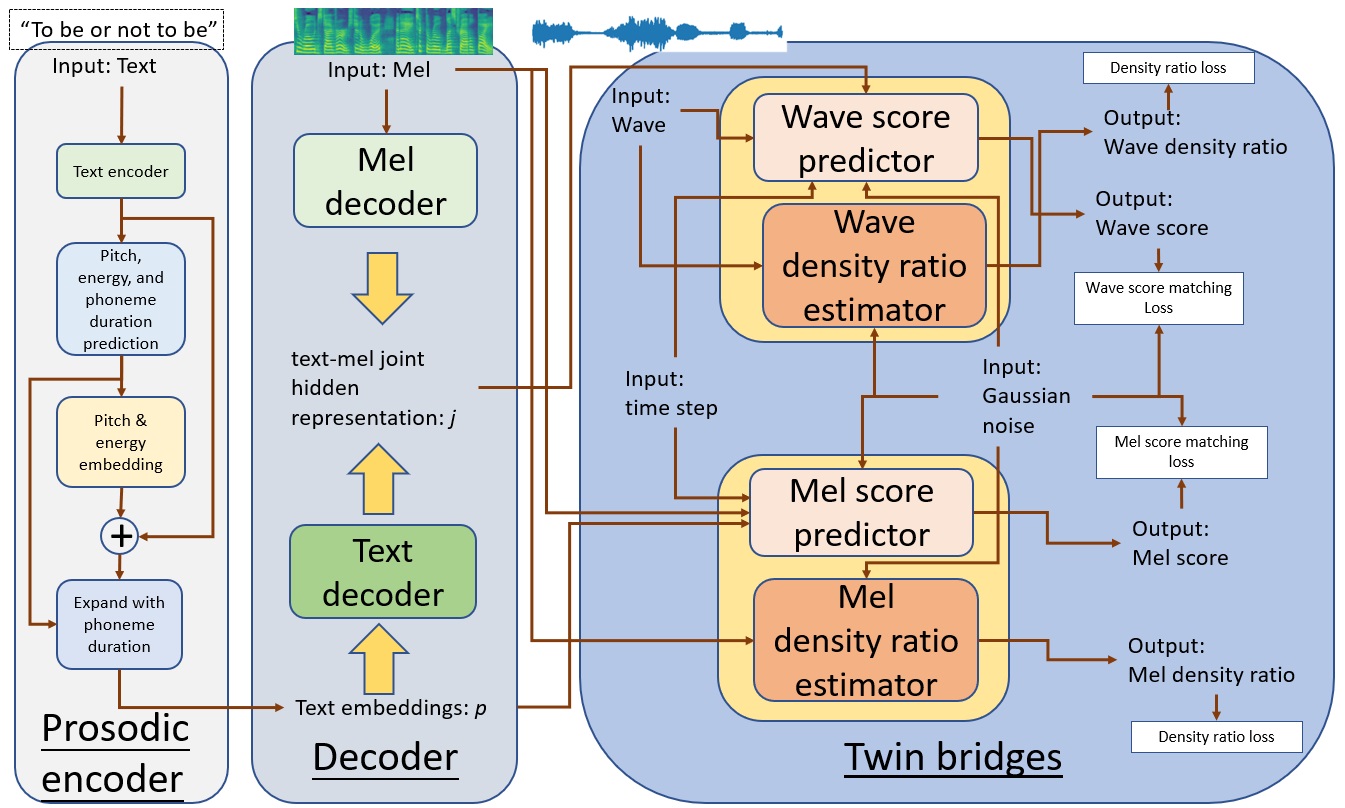
The overall structure of Schron.
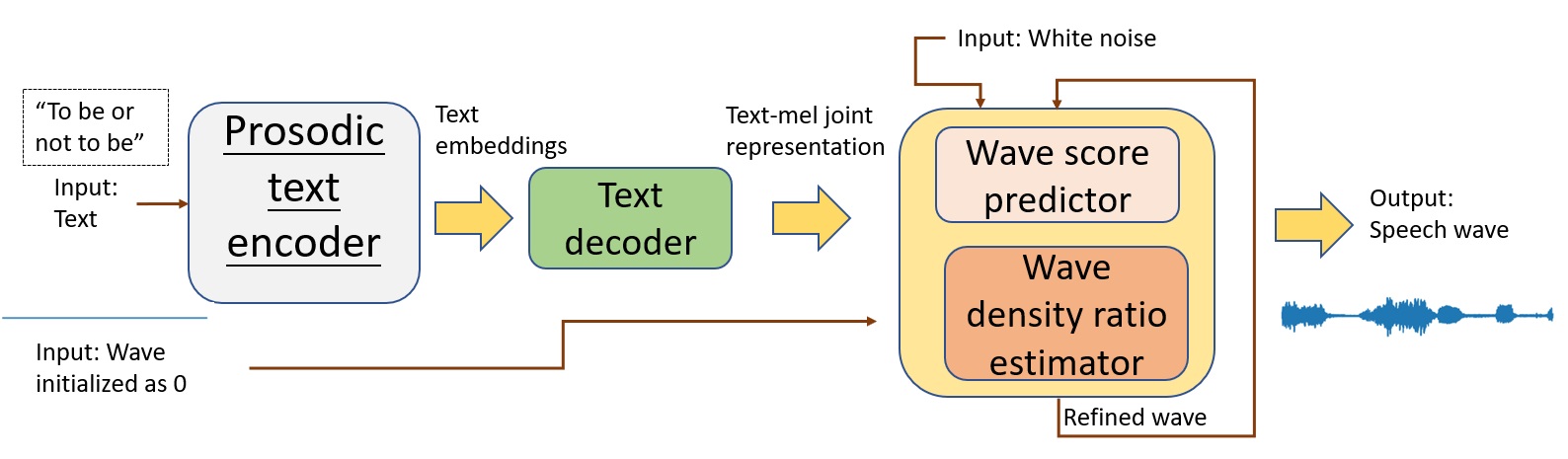
The inference pipeline of Schron.
Example of two-stage wave generation in Schron.
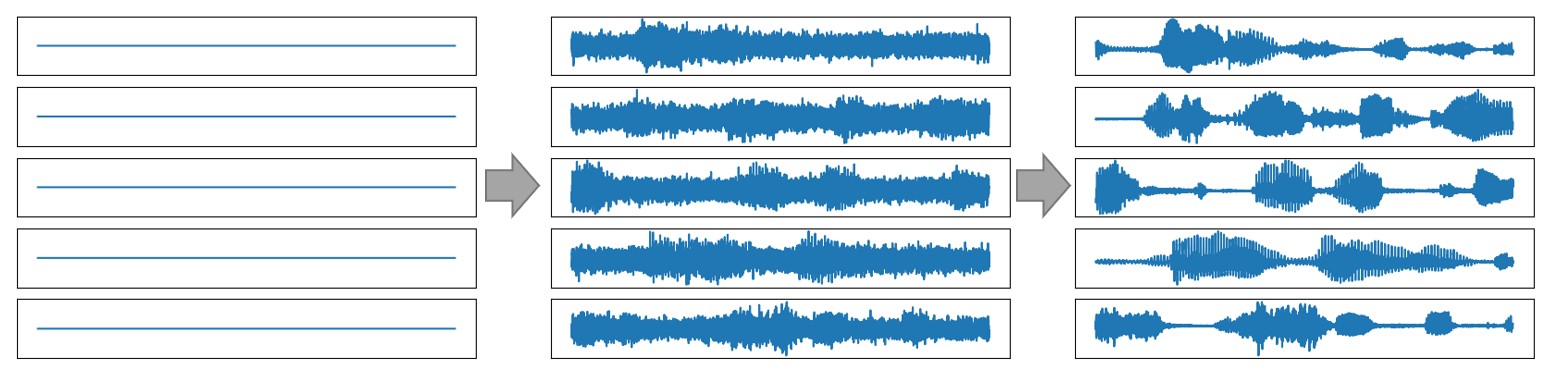
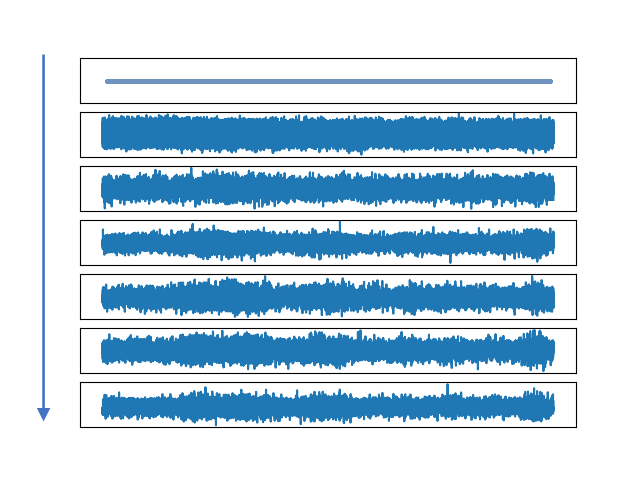
Two stages of wave generation in Schron. (a)The generation steps of the noisy wave from Dirac's delta distribution in the first stage. (b)The generation steps of the clean wave from the noisy wave in the second stage.
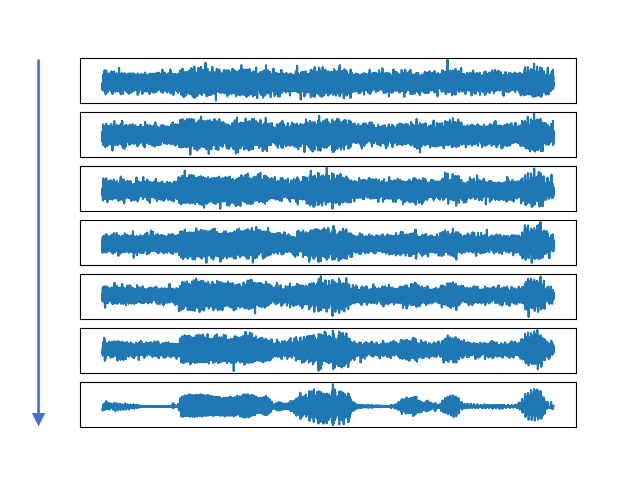
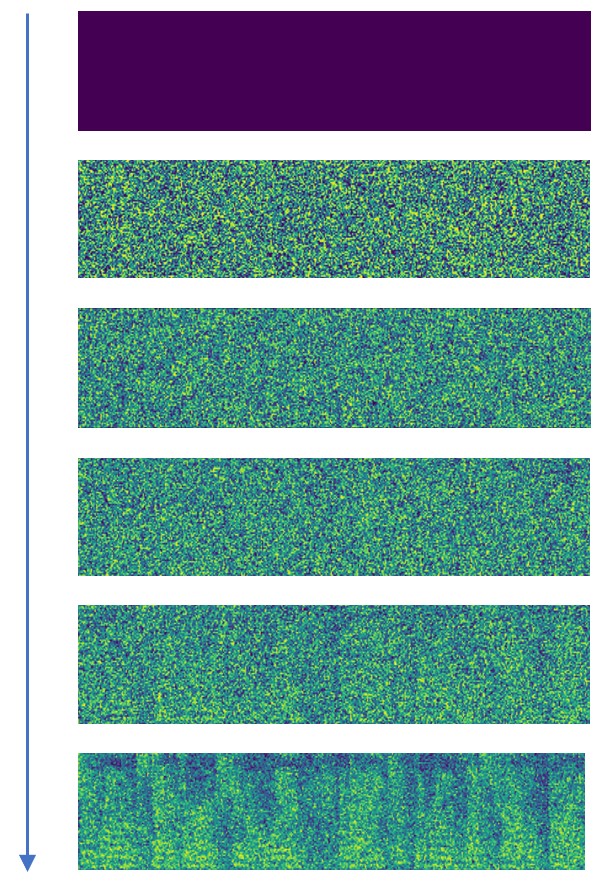
Two stages of mel-spectrogram generation in Schron. (a) The generation steps of noisy mel-spectrogram from Dirac distribution in the first stage. (b) The generation steps of clean mel-spectrogram from noisy mel-spectrogram in the second stage.

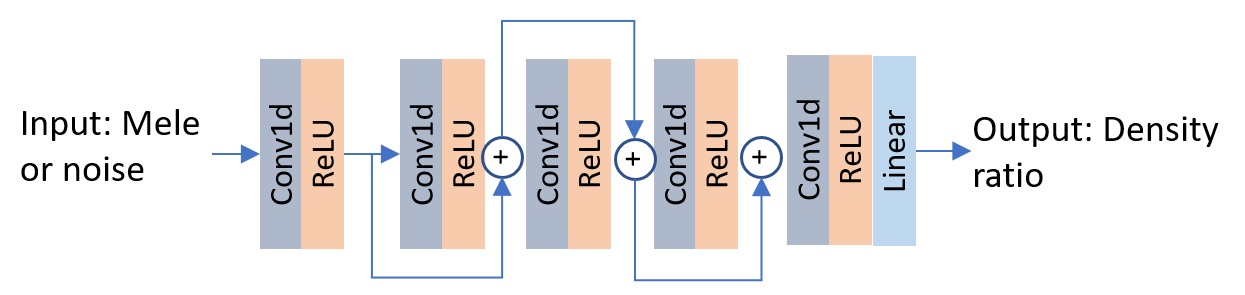
The mel density ratio prediction network in Schron.
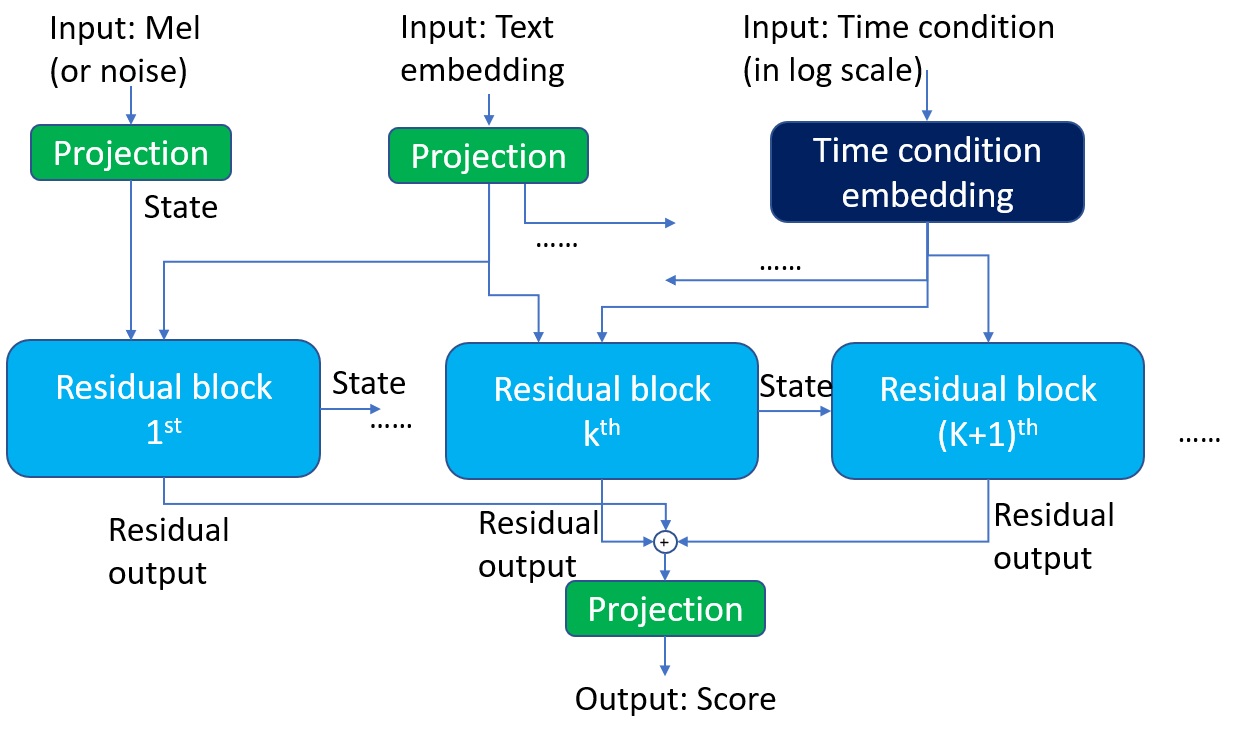
The mel score prediction network in Schron.
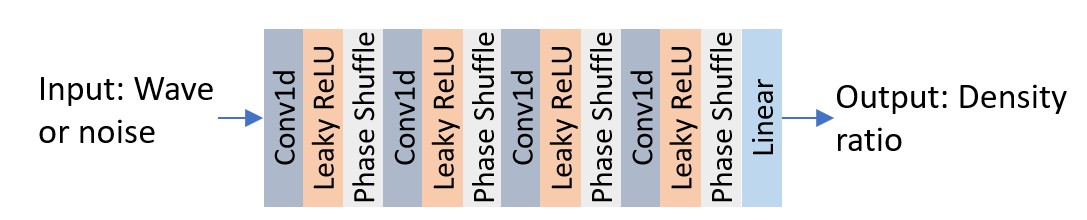
The wave density ratio prediction network in Schron.
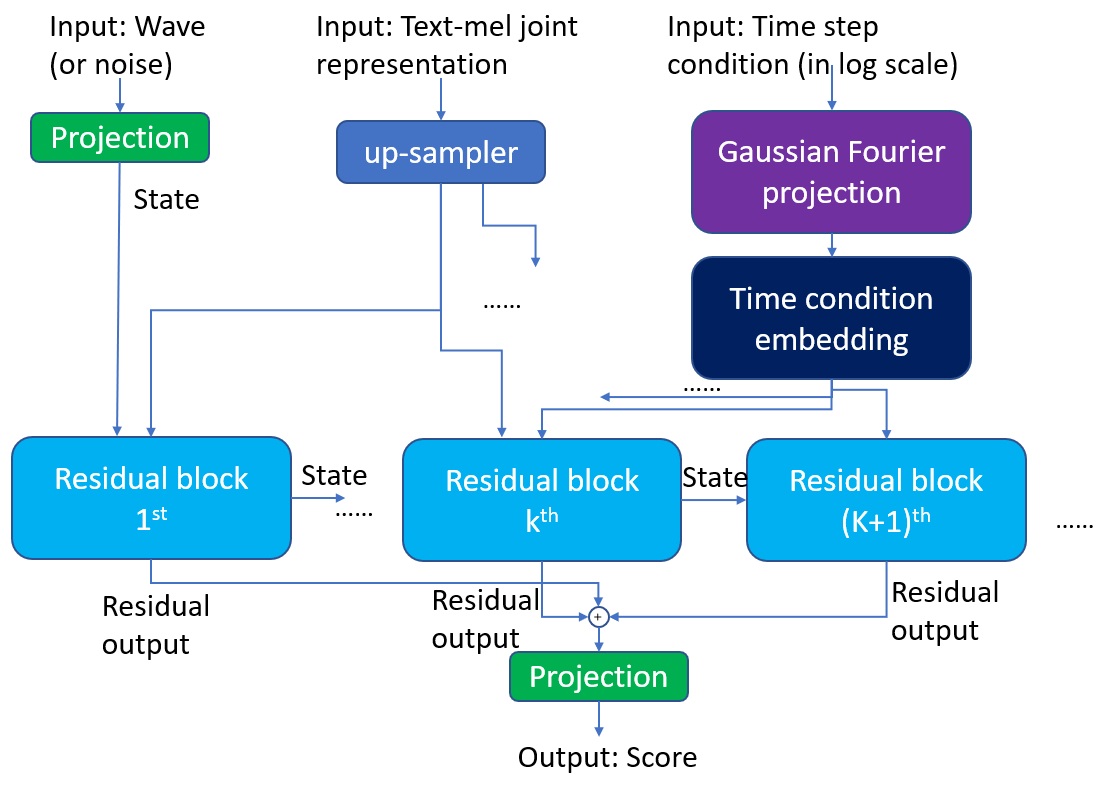
The wave score prediction network in Schron.
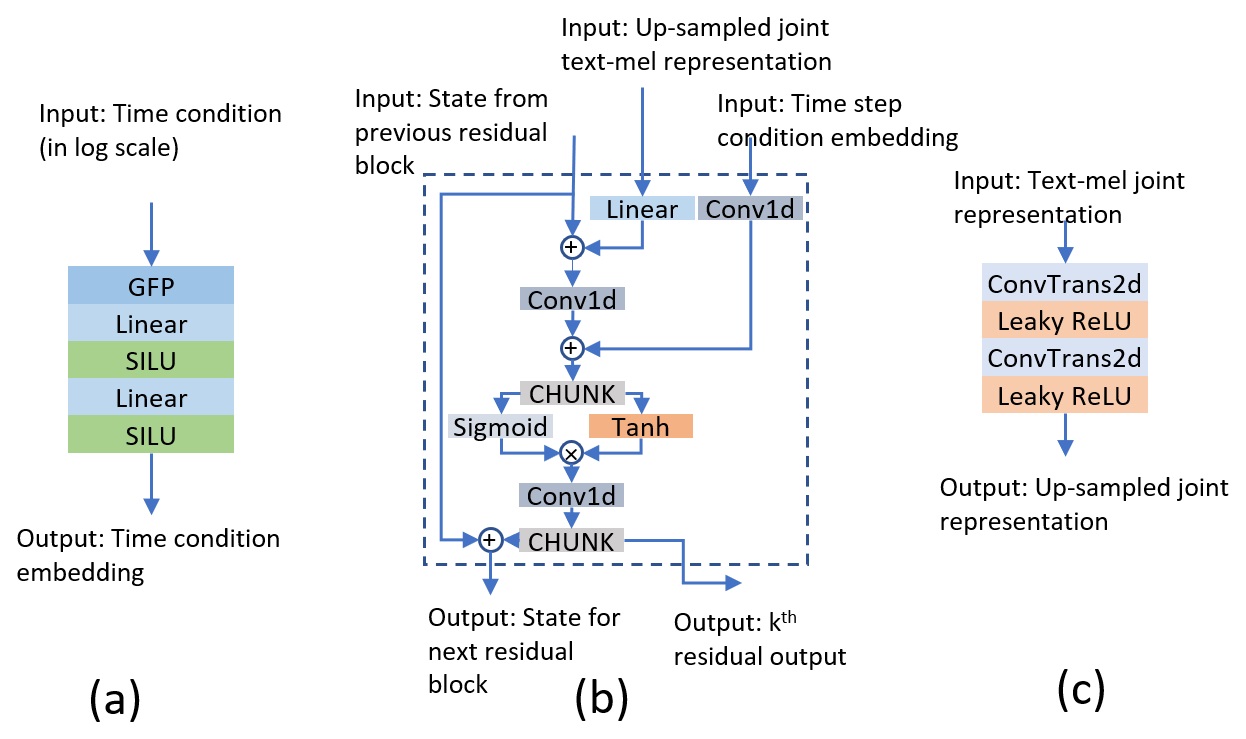
Modules in score prediction network. (a) Time step embedding; (b) the residual block; (c) up-sampling of text representations.